
Learning to classify video data from classes not included in the training data, i.e. video-based zero-shot learning, is challenging. We conjecture that the natural alignment between the audio and visual modalities in video data provides a rich training signal for learning discriminative multi-modal representations. Focusing on the relatively underexplored task of audio-visual zero-shot learning, we propose to learn multi-modal representations from audio-visual data using cross-modal attention and exploit textual label embeddings for transferring knowledge from seen classes to unseen classes. Taking this one step further, in our generalised audio-visual zero-shot learning setting, we include all the training classes in the test-time search space which act as distractors and increase the difficulty while making the setting more realistic. Due to the lack of a unified benchmark in this domain, we introduce a (generalised) zero-shot learning benchmark on three audio-visual datasets of varying sizes and difficulty, VGGSound, UCF, and ActivityNet, ensuring that the unseen test classes do not appear in the dataset used for supervised training of the backbone deep models. Comparing multiple relevant and recent methods, we demonstrate that our proposed AVCA model achieves state-of-the-art performance on all three datasets.
Introduction
The majority of zero-shot learning(ZSL) methods are developed for image classification and action recognition, but they use only unimodal input. However, humans in day-to-day activities leverage muti-modal sensory inputs.
One example where multi-modal sensory inputs are required is when a dog is barking, but the dog is visually occluded. In this case, a human can not understand the scene when relying on visual information alone. Using multiple modalities, such as vision and sound, allows gathering context and capture complementary information to better understand the environment.
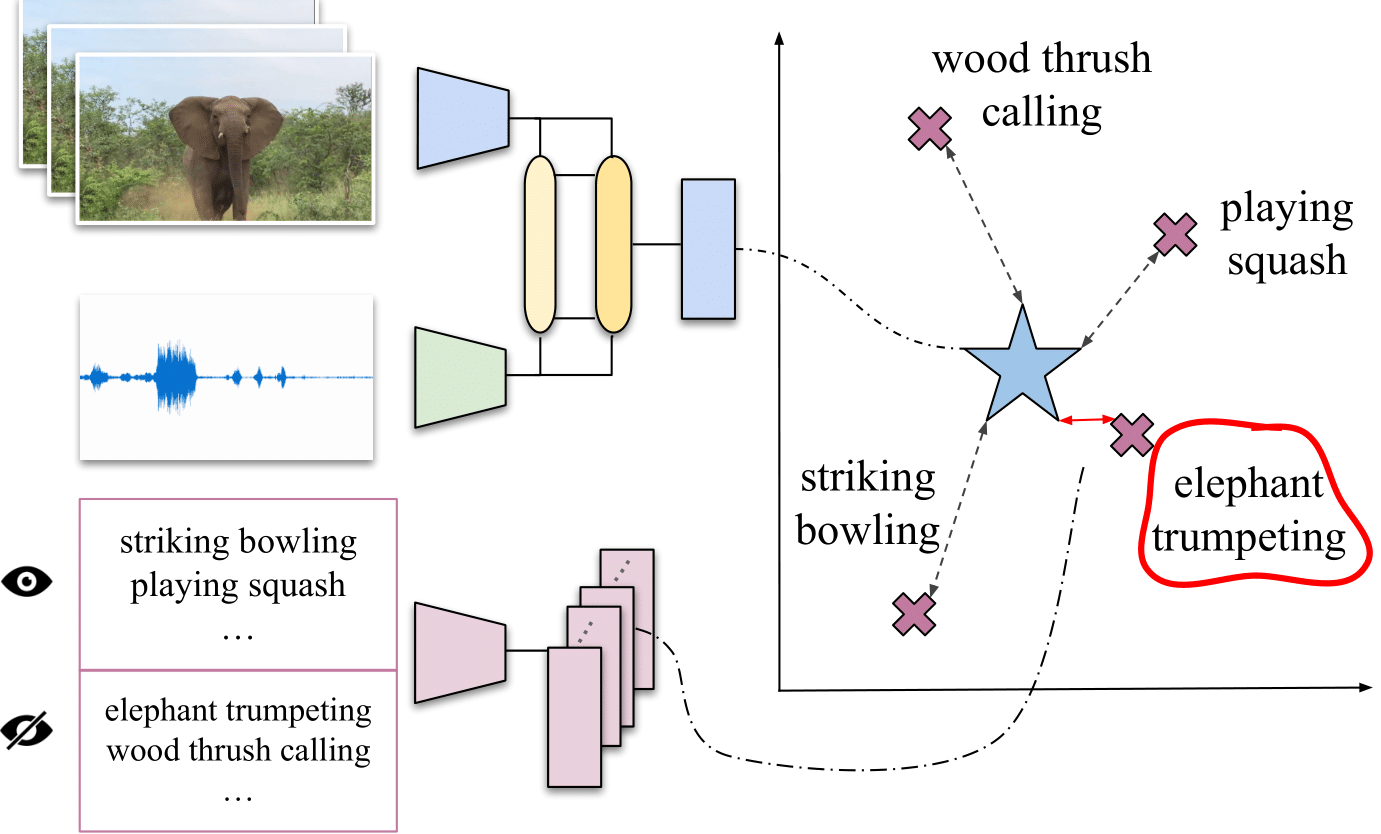
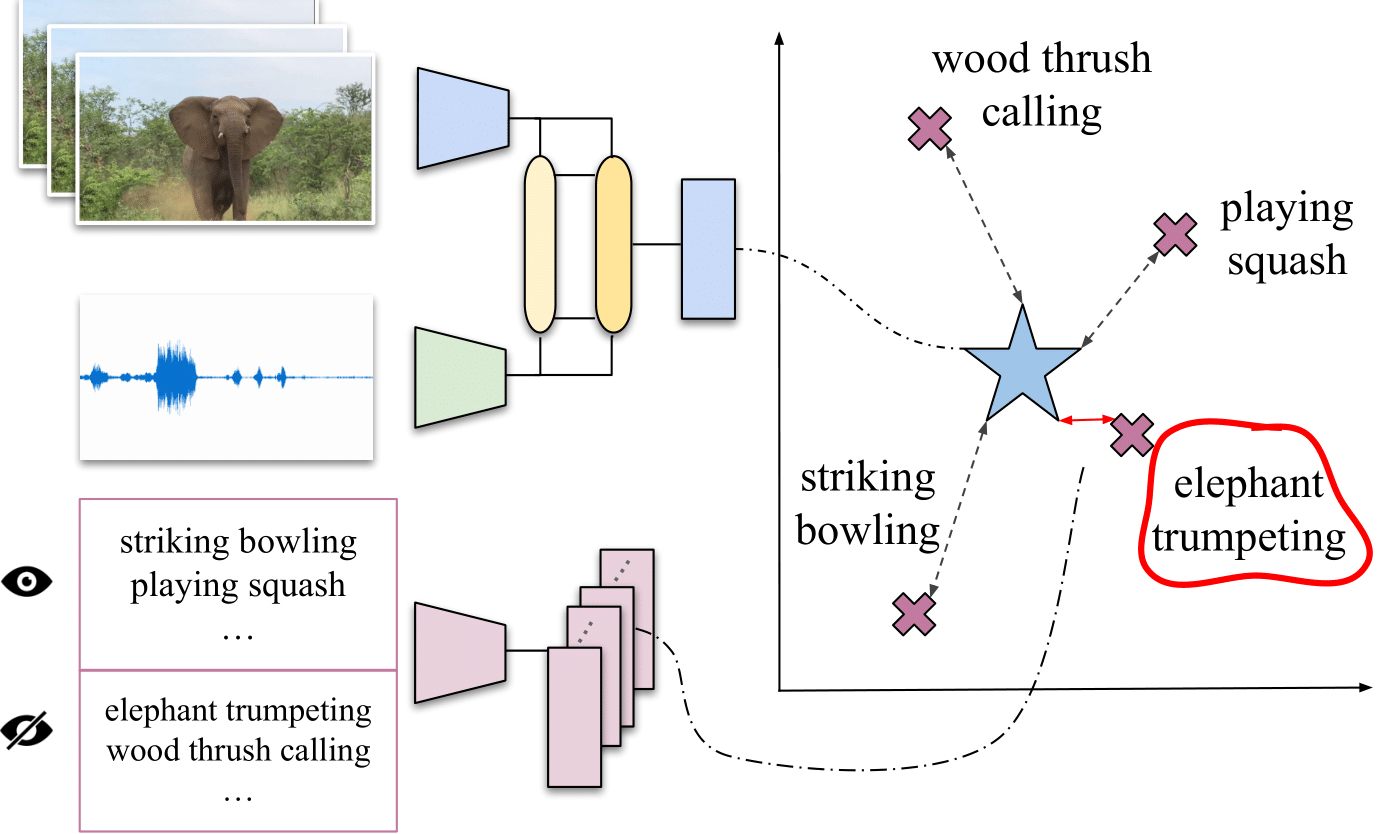
The goal of the paper is to provide a model that can classify videos from classes never seen during training. More specifically, we want that the BLUE STAR in the image below to be as close as possible to the RED X for the correct class, even if the correct class is a class never seen during training.
More formally, we denote the training set consisting only of samples from seen classes by , where are visual and audio features respectively, is the corresponding ground-truth class , and is the number of samples in the training set. We refer to the class-level text embedding for class as . The goal is to learn a function which can then also be applied to samples from unseen classes , where for the set of test samples from unseen classes with samples.
To summarize our contributions:
- We introduce three novel benchmarks for audio-visual generalized zero-shot learning(GZSL) curated from VGGSound, UCF101 and ActivityNet datasets.
- We propose AVCA (Audio-Visual Cross-Attention) framework which leverages cross-modal attention between audio and visual information.
- We show that AVCA yields state-of-the-art performance on all proposed audio-visual GZSL benchmarks, outperforming the state-of-the-art unimodal and multi-modal zero-shot learning methods. Furthermore, we provide qualitative analysis of the learnt multi-modal embedding space, demonstrating well-separated clusters for both seen and unseen classes.
Audio-Visual GZSL Benchmarks
We introduce three new benchmarks based on VGGSound, UCF101 and ActivityNet. The previous benchmarks for audio-visual GZSL had an overlap between validation and test classes, which would leak information about test classes during training. To avoid this, our benchmarks are split into training (TRAIN), validation (VAL) and testing (TEST). The unseen classes from VAL do not overlap with the unseen classes from TEST. Moreover, the samples from TRAIN+VAL are different from those in TEST.
To correctly set the hyperparameters and train the system, we employ a 2-stage training protocol:
- The first stage comprises on training on TRAIN and choosing the hyperparameters on VAL. VAL also contain classes unseen in TRAIN, so VAL tries to approximate the ZSL scenario.
- In the second stage, we retrain the system on TRAIN+VAL using the previously selected hyperparameters.
- Finally, we evaluate the system on TEST.
Model and losses
The goal of our model is to be able to fuse information from both modalities. For fusing information from multiple modalities, we use a cross-attention block based on the Transformer architecture. AVCA has two outputs heads, one for each input modality, and these are used to provide a richer training signal.
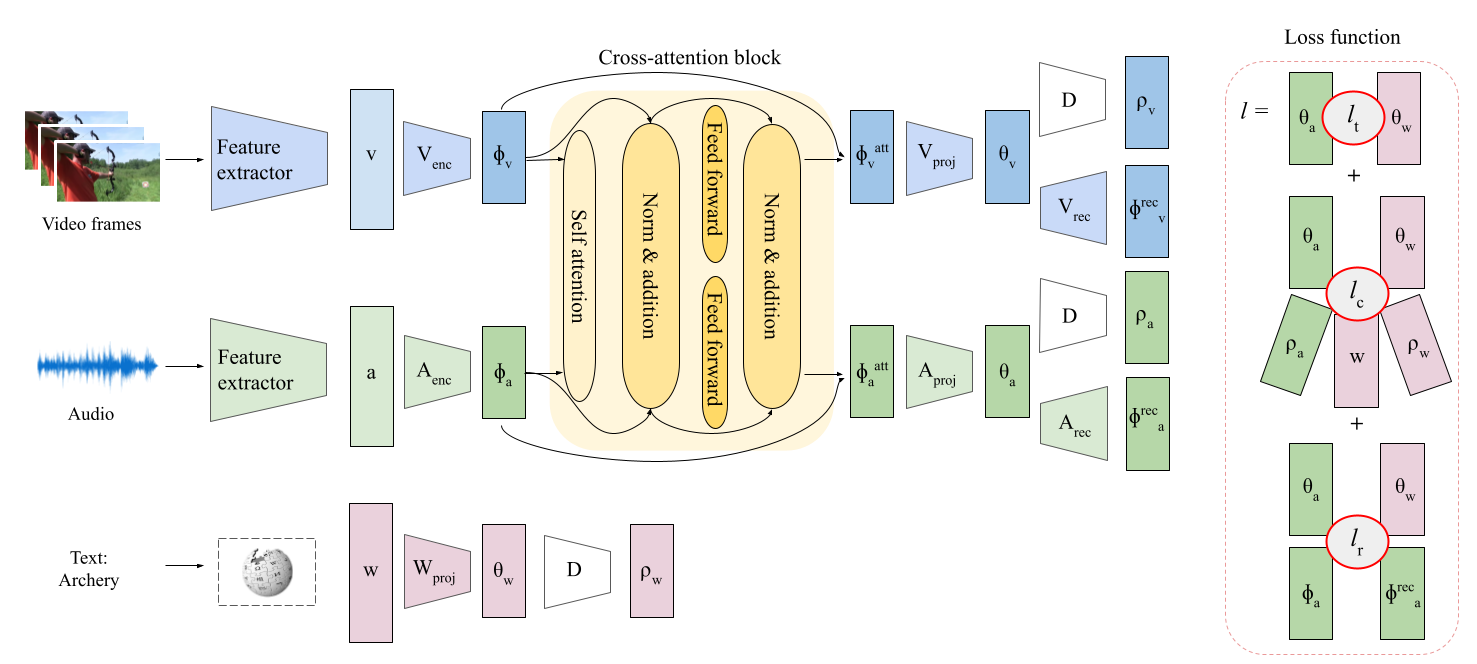
Given the above architecture, at test time, class predictions are obtained by determining the class that corresponds to the textual class label embedding that is closest to the multi-modal representation (in our experiments we found that using gave slightly weaker results):
We also use different types of losses, such as:
- Triplet losses on different components in our model, whose goal is to help the model learn a discriminative representation.
- Reconstruction losses, which makes sure that each modality contain a significant amount of information about the semantics of the correct class.
- Regularization losses, whose goal is to make sure that each branch still contains a significant amount of information about itself.
Quantitative results
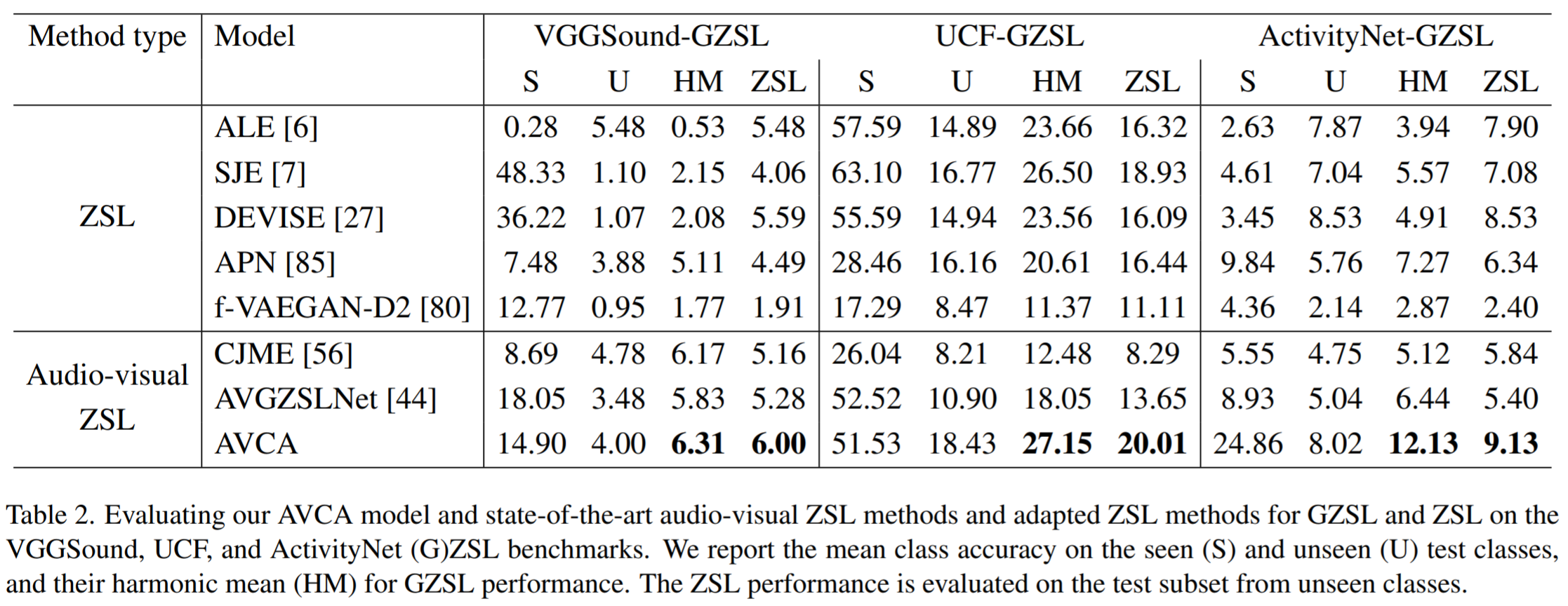
It can be observed that AVCA obtains the best performance on all 3 datasets. The first 5 methods presented were initially designed for (G)ZSL on images, but we adapted them for (G)ZSL using multimodal inputs. CJME and AVGZSSLNet are methods specifically designed for multi-modal (G)ZSL.
Qualitative results
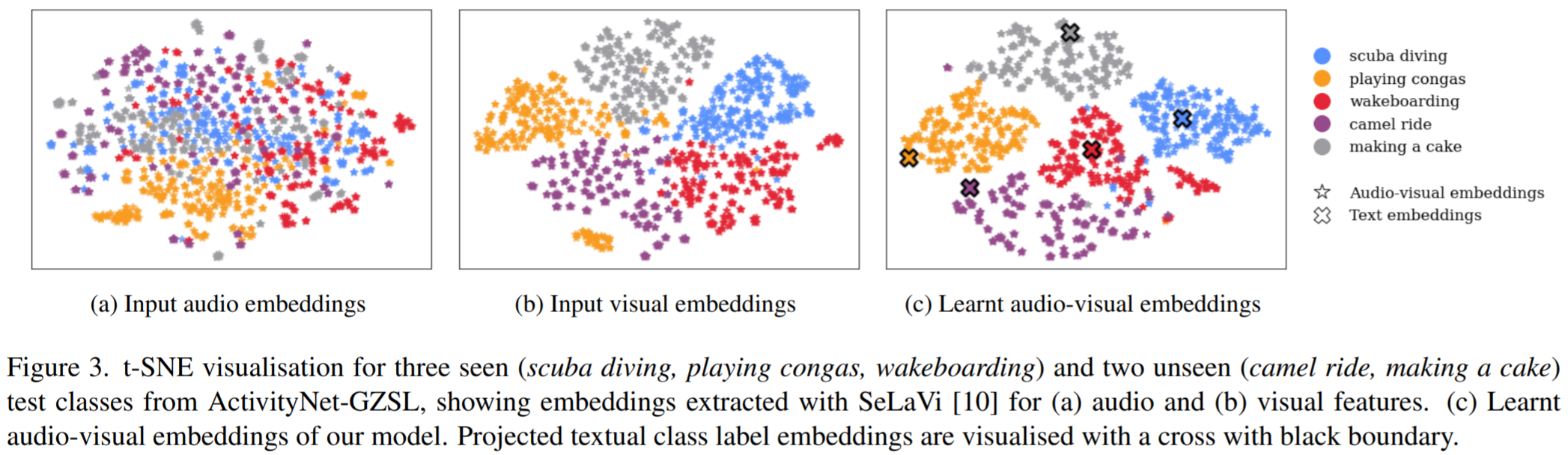
From the qualitative results, it can be observed that the visual embeddings are slightly better clustered than the audio embeddings. However, our learnt audio-visual embedding is much better clustered than both the visual and audio input embeddings. Moreover, it can also be observed that the class embeddings are projected inside each cluster, meaning that the clusters also retain significant information about the semantics of each class.
For more results and analysis, please refer to the paper.