
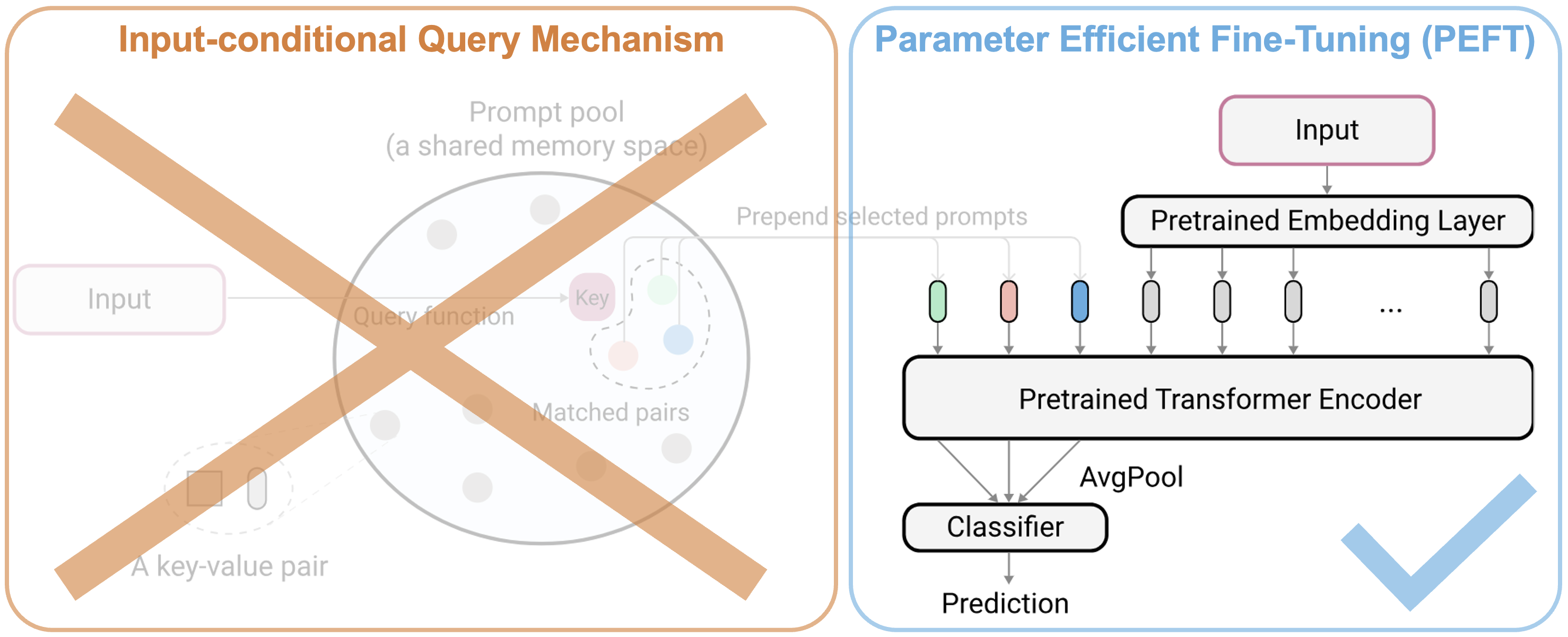
With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show (1) P-RFCL techniques relying on input-conditional query mechanisms work not because but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods. Together, we believe our insights contribute to a more grounded treatment of CL with pretrained models.
Start Here
Continual learning (CL) is still a challenging frontier in machine learning. The main goal of CL is to enable models to learn continuously from a stream of data, adapting to new tasks while retaining knowledge from previous ones. This is particularly difficult due to the phenomenon known as catastrophic forgetting, where a model’s performance on previous tasks degrades as it learns new ones.
With the rise of foundation models, the focus in continual learning has shifted from training models from scratch to adapting large-scale pre-trained models to solve standard continual learning tasks, often without using a memory buffer, i.e. rehearsal-free continual learning (RFCL).
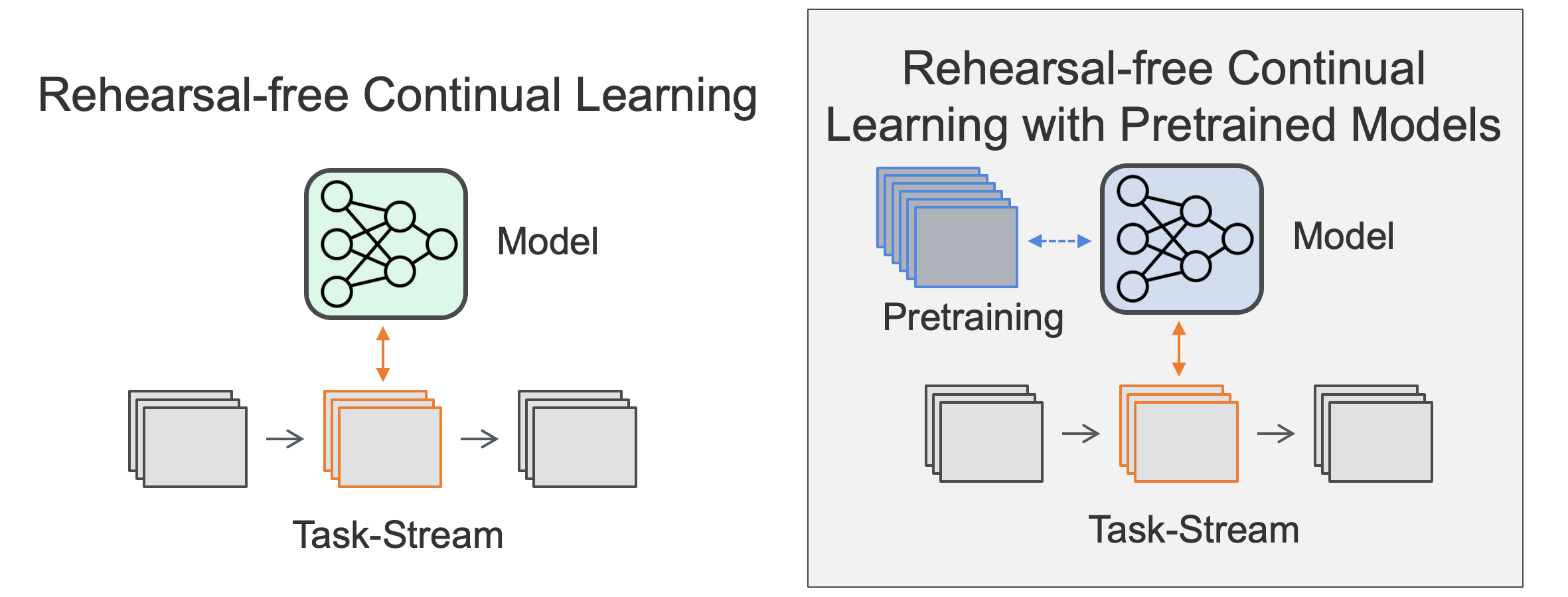
Our study examines the effectiveness of using parameter-efficient finetuning techniques (PEFT) in RFCL and delves into the true reasons behind their strong performances. We address important questions about the methods and assumptions underlying P-RFCL (PEFT-style RFCL) approaches.
Motivation
The motivation behind our study comes from recent observations in the CL community. It has been noted that simple non-parametric baselines and first-task adaptations can achieve competitive results compared to more complex P-RFCL methods. This raises important questions about these methods' actual contributions and superiority in benchmark performances. To better understand and contextualize P-RFCL, we conducted a series of experiments to answer the following research questions:

These research questions look into the methods that made P-RFCL popular, specifically input-based query mechanisms like Learning-to-Prompt (Wang et al., 2022), as well as the broader field of P-RFCL and its role in current and past RFCL literature.
Key Insights
We have discovered several significant findings that challenge current ideas in the field of RFCL with pretrained models, as answers to the proposed research questions.
[A] Query-based P-RFCL methods work by collapsing towards simple PEFT.
One of the primary insights from the study is that P-RFCL techniques relying on input-conditional query mechanisms do not perform well due to the mechanisms themselves but rather despite them. These methods tend to collapse towards simpler PEFT shortcut solutions.
Detailed Findings:
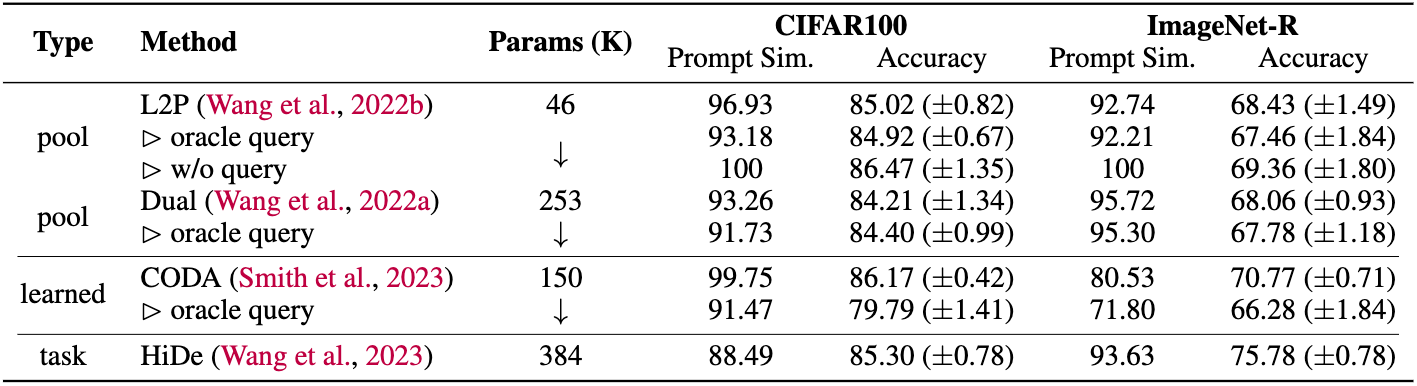
- Query Collapse: Our study reveals that query-based P-RFCL methods, such as Learning-to-Prompt (L2P) (Wang et al., 2022a), often converge to solutions where the query mechanism becomes redundant. Instead of learning diverse and context-specific prompts, the models frequently use very similar or even identical prompts across different tasks.
- Oracle Query: Experiments on artificially diversifying the learned prompts via an oracle query function reveal that these query-based P-RFCL methods do not work despite but because of their collapse to simple PEFT. We attribute this phenomenon to the fact that more diverse, and thus more specific, adaptations lead to increased forgetting, hurting the overall performance.
- Simplification: Our experiments further show that removing or simplifying the query mechanism can lead to better performance. This indicates that the added complexity of query-based methods might not be justified.
[B] Most P-RFCL methods are matched by simple PEFT and variations on top are often superfluous.
Most P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. Our study demonstrates that the performance gains attributed to P-RFCL methods are often due to the underlying PEFT rather than the additional complexities introduced by query mechanisms.
Detailed Findings:
- Baseline Comparison: We introduce a baseline method, OnlyPrompt, which uses a straightforward PEFT approach without any complex query mechanisms. This method performs on par with or better than existing P-RFCL methods across a diverse set of benchmarks.
- Parameter Efficiency: OnlyPrompt achieves these results while using significantly fewer parameters, highlighting the efficiency of simple PEFT techniques.

[B] Prompt-based PEFT operates in benchmark-beneficial regimes via tunable parameter count choices.
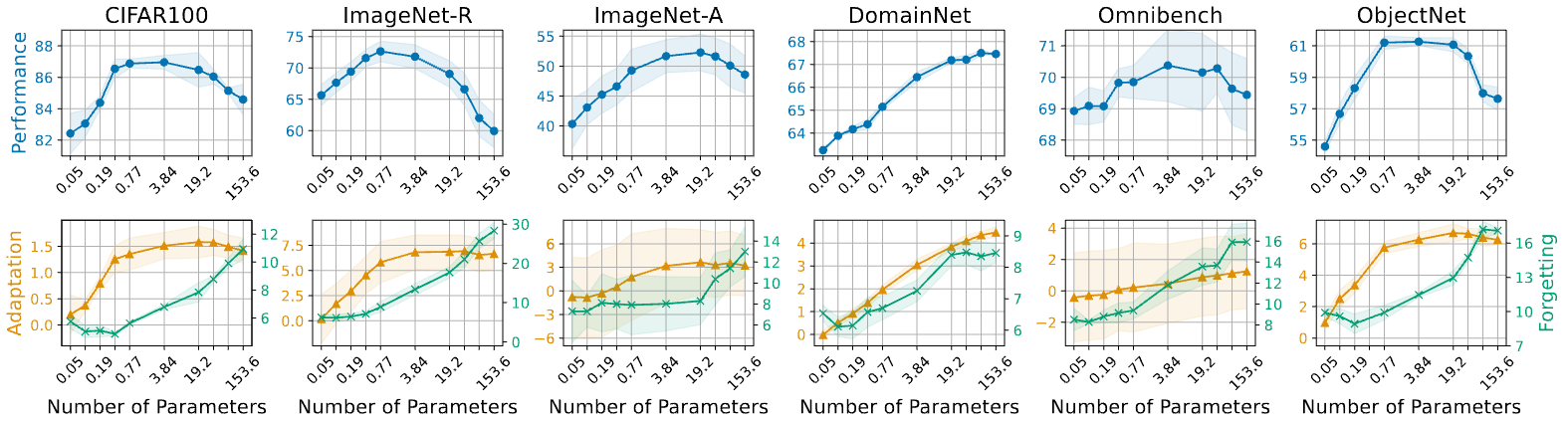
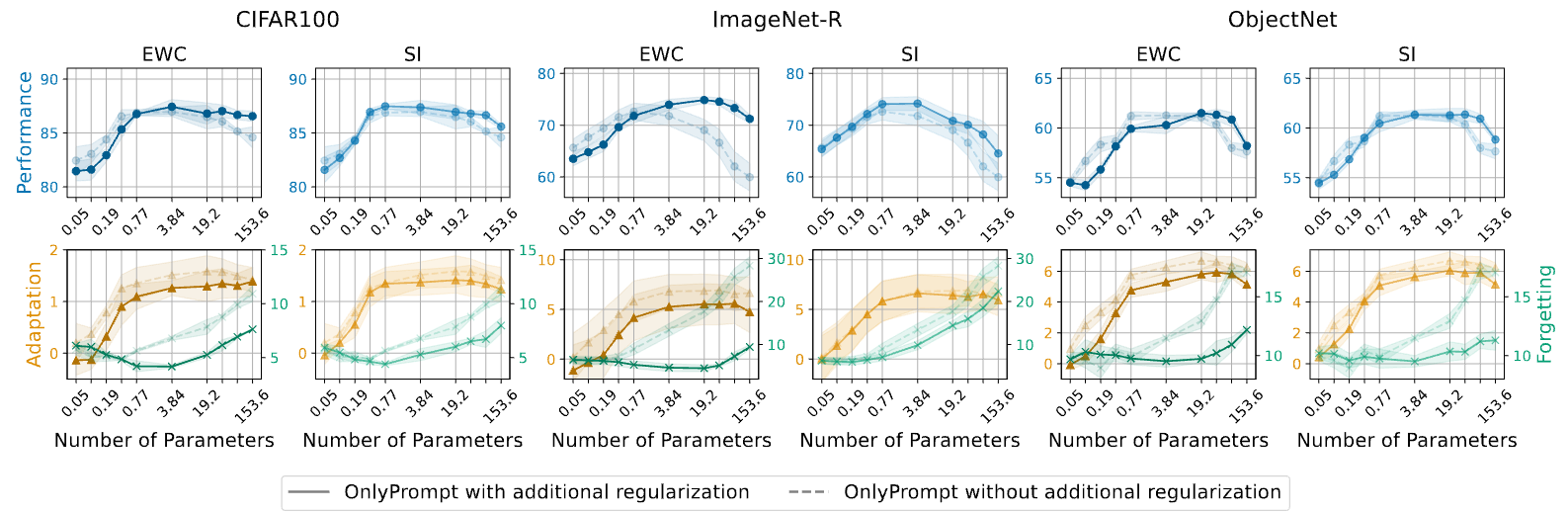
We found that the limit on adjustable parameters is crucial for the success of RFCL approaches. This limit helps maintain a balance between adapting to new tasks and retaining what has been learned, reducing the risk of forgetting important knowledge.
Detailed Findings:
- Parameter Trade-off: Our study finds that there is an optimal range for the number of tunable parameters that balances adaptation and forgetting. Too few parameters lead to insufficient adaptation, while too many parameters increase the risk of forgetting.
- Robustness Across Benchmarks: This optimal parameter range is consistent across various benchmarks, indicating a general principle that can guide the design of future RFCL methods.
[C] P-RFCL still has merit despite recent first-task adaptation works.
Our research compares the benefits of adapting continually versus adapting on only the first task. Although adapting for the first task shows good performance, our results suggest that adapting models across the entire data stream results in significant improvements in robustness and accuracy.
Detailed Findings:
- Comparative Analysis: We compare first-task adaptation methods, such as Nearest Mean Classifier (NMC) and ADAM (Zhou et al., 2023), against full adaptation approaches like OnlyPrompt. The results show that full adaptation outperforms first-task adaptations across multiple benchmarks.
- Robustness and Stability: Full adaptation methods show a higher level of stability, especially in situations with large differences between tasks.

[D] Standard regularization-based CL can improve performance and robustness for P-RFCL.
We find that traditional RFCL techniques like Elastic Weight Consolidation (EWC) and Synaptic Intelligence (SI) still have value in the age of pretrained foundation models. These methods can improve the performance and strength of PEFT-style P-RFCL methods.
Detailed Findings:
- Integration with PEFT: Our study explores the integration of EWC and SI with the OnlyPrompt baseline. We find that these regularization techniques can further reduce forgetting and improve overall performance.
- Orthogonal Benefits: The combination of standard RFCL techniques with PEFT methods provides orthogonal benefits, suggesting that these approaches can be complementary rather than mutually exclusive.
Conclusion
Our work provides a more grounded understanding of rehearsal-free continual learning with pretrained models. By highlighting the central role of simple PEFT and the limitations of complex query mechanisms, we advocate for a more straightforward approach to continual learning. We also emphasize the ongoing relevance of traditional RFCL methods in combination with modern PEFT techniques.
Key Takeaways
- Simplify When Possible: Complex query mechanisms in P-RFCL may not provide the expected benefits and can often be replaced by simpler PEFT approaches.
- Focus on Parameter Efficiency: The number of tunable parameters is a critical factor in achieving a balance between adaptation and retention.
- Combine Approaches: Traditional RFCL methods like EWC and SI still have a place in the modern landscape of continual learning and can complement PEFT methods effectively.
Future Directions
The insights presented in our paper pave the way for more principled research in P-RFCL, encouraging a focus on simplicity and efficiency while leveraging the strengths of pretrained models. As the field progresses, it is crucial to develop diverse benchmarks that accurately reflect practical use cases to assess the true efficacy of emerging methods.