
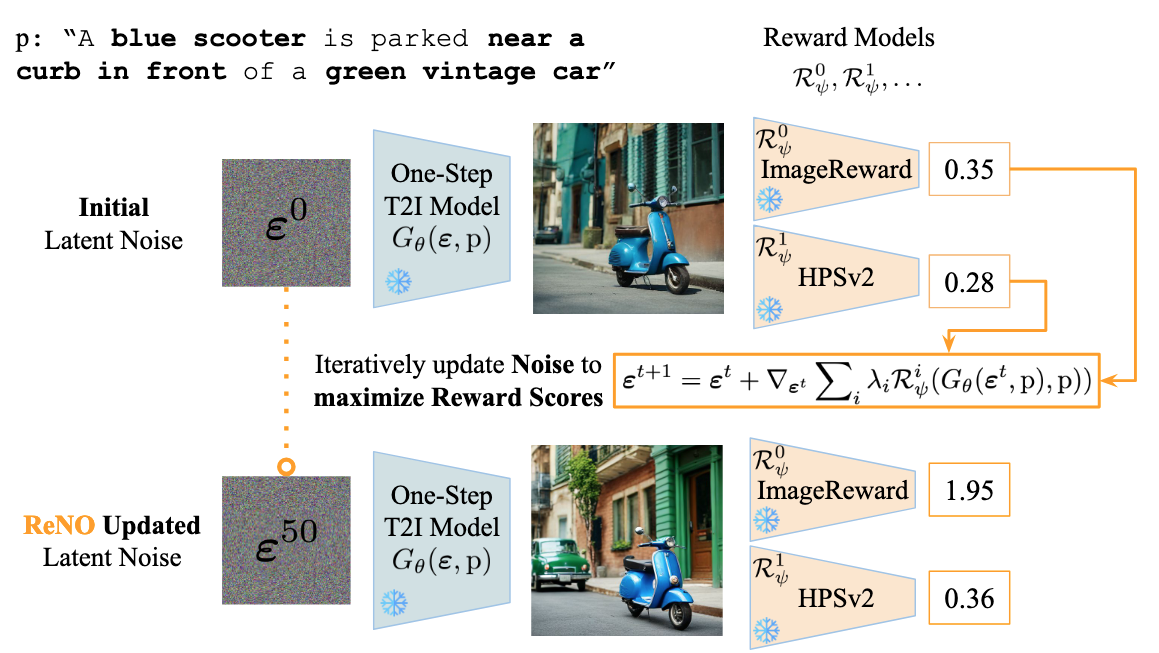
Text-to-Image (T2I) models have made significant advancements in recent years, but they still struggle to accurately capture intricate details specified in complex compositional prompts. While fine-tuning T2I models with reward objectives has shown promise, it suffers from "reward hacking" and may not generalize well to unseen prompt distributions. In this work, we propose Reward-based Noise Optimization (ReNO), a novel approach that enhances T2I models at inference by optimizing the initial noise based on the signal from one or multiple human preference reward models. Remarkably, solving this optimization problem with gradient ascent for 50 iterations yields impressive results on four different one-step models across two competitive benchmarks, T2I-CompBench and GenEval. Within a computational budget of 20-50 seconds, ReNO-enhanced one-step models consistently surpass the performance of all current open-source Text-to-Image models. Extensive user studies demonstrate that our model is preferred nearly twice as often compared to the popular SDXL model and is on par with the proprietary Stable Diffusion 3 with 8B parameters. Moreover, given the same computational resources, a ReNO-optimized one-step model outperforms widely-used open-source models such as SDXL and PixArt-alpha, highlighting the efficiency and effectiveness of ReNO in enhancing T2I model performance at inference time.
Demo
For all details, please refer to the paper, our code, and our demo
Helmholtz AI Best Paper Award
We are delighted to share that our paper received the Helmholtz AI Best Paper award for the year 2024. More details can be found here. Additionally, ReNO has been covered in the MCML Research Insight.