
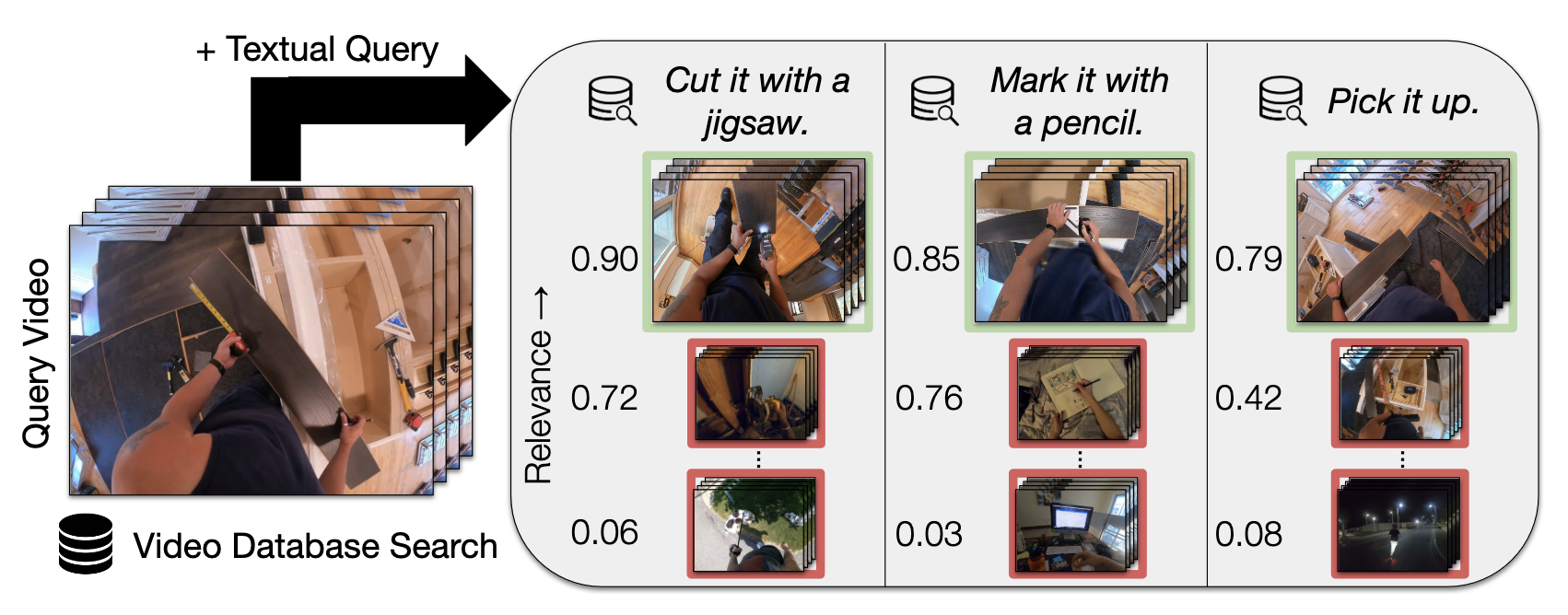
In Composed Video Retrieval, a video and a textual description which modifies the video content are provided as inputs to the model. The aim is to retrieve the relevant video with the modified content from a database of videos. In this challenging task, the first step is to acquire large-scale training datasets and collect high-quality benchmarks for evaluation. In this work, we introduce EgoCVR, a new evaluation benchmark for fine-grained Composed Video Retrieval using large-scale egocentric video datasets. EgoCVR consists of 2,295 queries that specifically focus on high-quality temporal video understanding. We find that existing Composed Video Retrieval frameworks do not achieve the necessary high-quality temporal video understanding for this task. To address this shortcoming, we adapt a simple training-free method, propose a generic re-ranking framework for Composed Video Retrieval, and demonstrate that this achieves strong results on EgoCVR.
Introduction
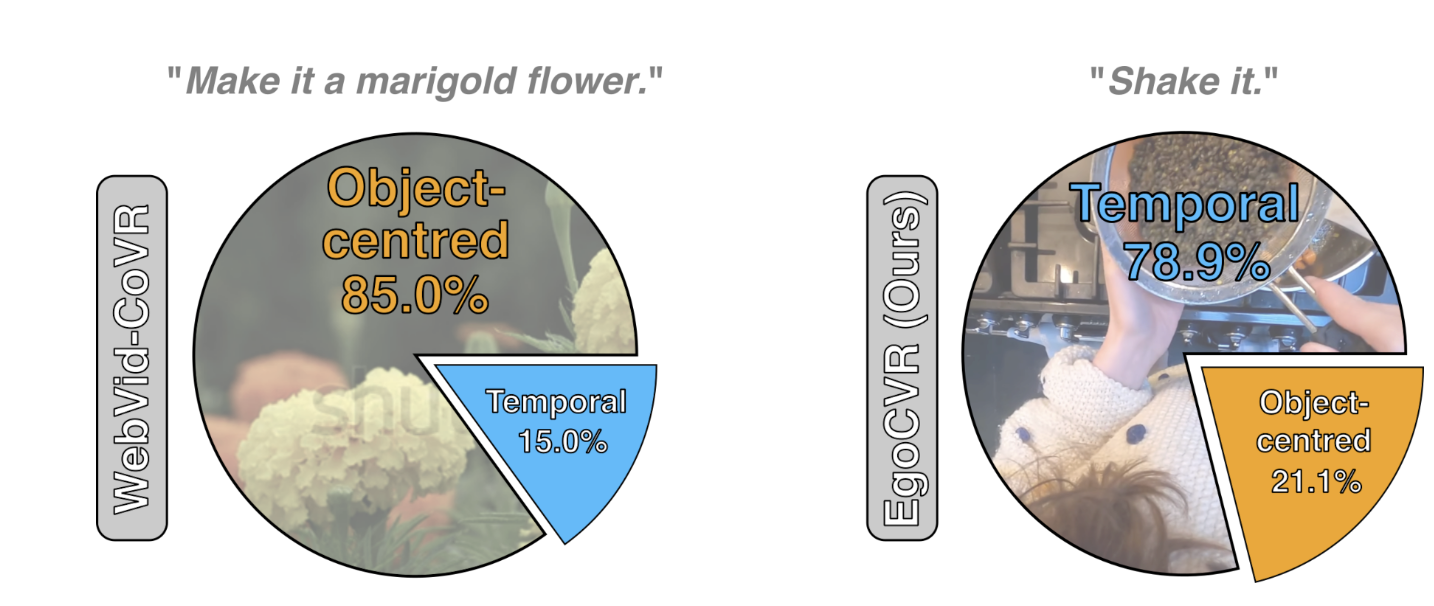
Composed Video Retrieval (CVR) is the task of understanding both the input video and the textual query and retrieving the relevant target video. While there has been a lot of work in the case of images with Composed Image Retrieval, there has been much less work in the case of videos. The only benchmark for Composed Video Retrieval is the WebVid-CoVR dataset. Unfortunately, the dataset is quite limited, mostly focusing on object-level modifications, and not requiring temporal understanding.
EgoCVR
In this paper, we manually curate a high-quality dataset EgoCVR consisting of 2295 evaluation triplets. This is extracted from the Ego4D dataset. The main benefit of the manual curation is that the dataset focuses heavily on temporal understanding, especially when compared to WebVid-CoVR.

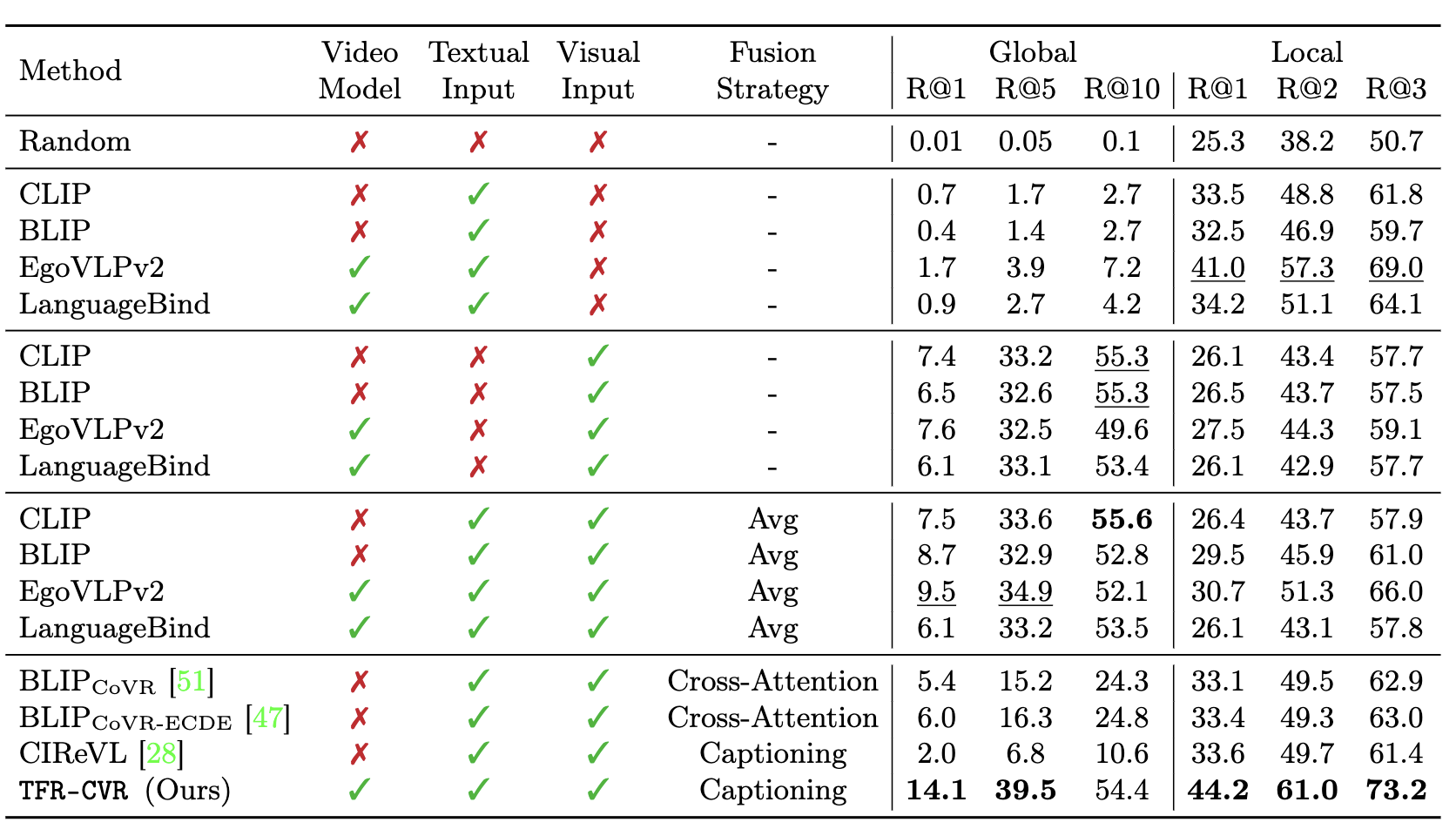
We evaluate existing models on this task, and they fail to perform well. Therefore, we propose TFR-CVR for this task. This is an effective application of "Vision-by-Language", where we caption the query video with a vision-language model, rewrite the caption with the instruction to get the target query, and then retrieve the target video using a text-video model. Additionally, we are able to improve performance by first applying visual filtering to restrict our gallery to the most visually similar samples.
Results
TF-CVR achieves state-of-the-art results on EgoCVR. We show some numbers and some examples below:
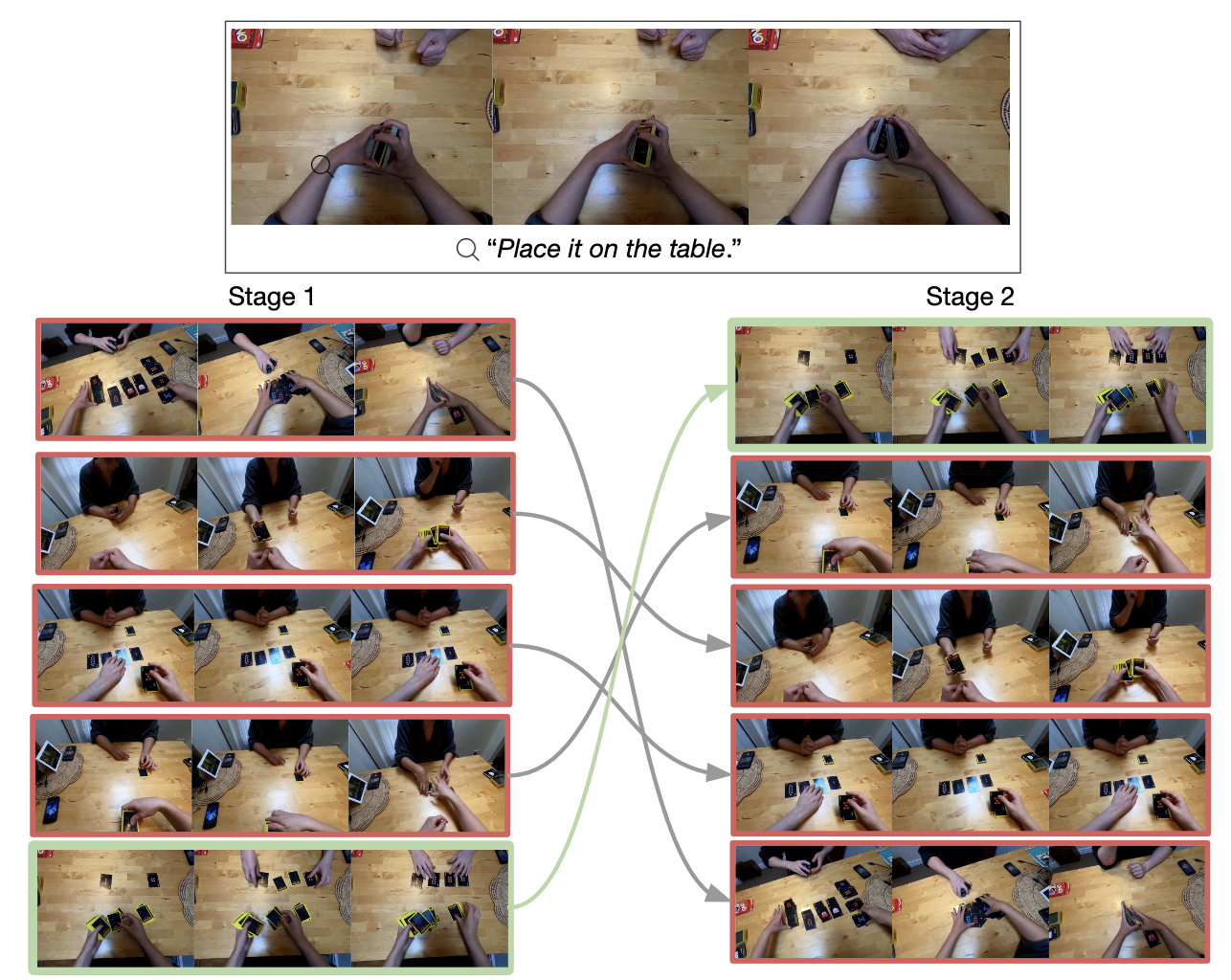
Re-Ranking plays an important role in improving the results, especially when there are lots of candidate videos in the gallery. We show an example of how visual filtering to first curate meaningful candidates improves results here.
We hope you found this interesting, for more results and analysis, please refer to the paper and our code.